Arquitectura cliente/servidor
El problema a resolver
En la historia de la informática, el ordenador no ha sido nunca un elemento aislado. Desde un principio se buscó mecanismos de conexión entre ordenadores de manera que se pudiese compartir la información entre ellos. A medida que el ordenador entraba en el mundo empresarial, este tipo de redes fue cobrando más importancia para compartir los datos entre distintos trabajadores. Cuanto más grande sea la empresa y de más ordenadores se disponga, las redes se hacen cada vez mas necesarias. Sin embargo aparece un problema debido a esta proliferación de ordenadores. Supongamos el siguiente ejemplo: una empresa tiene 30 trabajadores que utilizan un ordenador cada uno. Por regla general utilizan todos el mismo software, a saber, varias aplicaciones ofimáticas (procesador de texto, hoja de cálculo, etc), y un programa propio para la gestión de la empresa. Aunque en la actualidad esta carga de trabajo no tiene por que suponer un problema para un ordenador, el disponer de todos los recursos de la empresa en cualquier ordenador, en ocasiones puede ser muy caro o simplemente inviable. En el ejemplo propuesto, por ejemplo, la aplicación de gestión de la empresa posiblemente haga uso de una base de datos (con los clientes, facturación, presupuestos, etc), que deberá estar disponible y ser la misma para todos los usuarios. Si esta base de datos esta repetida en cada ordenador se corre el riego perder la consistencia de los datos, es decir, obtener bases de datos distintas en cada ordenador por estar trabajando cada usuario con una copia local. Una posible solución pasa por centralizar la aplicación de gestión en un único ordenador, al que se conecten todos los usuarios para realizar las operaciones. Esta no es una buena solución, ya que cualquier cambio en la aplicación (por ejemplo en el interface de usuario) supone modificaciones en toda la aplicación, al no existir una distinción clara entre las partes de la aplicación. La solución a este problema pasa por distribuir la aplicación en varias capas, y que cada capa ofrezca una serie de servicios a la capa superior. De esta manera podríamos disponer de tres capas, una el acceso a la base de datos, otra que implemente la lógica propia del negocio y otra que implemente el interface con el usuario. Cualquier cambio en una capa no influye al resto si se mantienen la misma interface entre capas. Además estas capas no tendrían que estar en el mismo equipo. Lo más común es que es el acceso a la base de datos se ejecute un ordenador que centralice la base de datos, e incluso, la lógica de negocio. De esta manera los de equipos de los usuarios se limitan a ejecutar la capa de interface con el usuario, requiriéndose para ello equipos menos potentes y por ello más baratos.
Esta es la estructura básica de la arquitectura cliente/servidor. Se dispone de un servidor que ofrece servicios, y una serie de clientes que los solicitan. Esta arquitectura tiene varias ventajas respecto a la tradicional no distribuida:
· Se evita la duplicidad de información y la perdida de coherencia en la información.
· Los clientes pueden ejecutarse en ordenadores menos potentes.
· Se separan las distintas partes de la aplicación favoreciendo la reutilización y facilitando el mantenimiento.
Breve historia de los sistemas distribuidos
Los sistemas distribuidos existen en el mundo de la informática en una u otra forma desde hace algún tiempo, aunque no se hayan llamado explícitamente sistemas distribuidos y no tuviesen la flexibilidad que tienen hoy en día. Al principio sólo existían los grandes ordenadores o mainframes en los que se ejecutaban Sistemas de gestión de Base de Datos (SGBD) jerárquicos. La conexión de los usuarios con el ordenador central se hacía mediante terminales tontas con conexiones punto a punto con el servidor. Los grandes ordenadores tenían un coste muy elevado y eran difíciles de mantener pero eran capaces de dar servicio a un número muy elevado de usuarios y tenían la ventaja (o desventaja) de ser administrados de forma centralizada. En este tipo de sistemas el software era monolítico, es decir, el interfaz de usuario, la lógica de negocio y el acceso a las bases de datos estaba todo contenido en una gran aplicación que se ejecutaba en el mainframe. Dado que las terminales utilizadas para conectarse al ordenador central no tenían ninguna capacidad de proceso, la aplicación entera se ejecutaba completamente en el ordenador central.
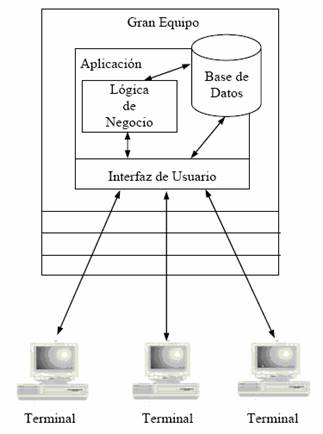
Ilustración 1. Arquitectura monolítica
La aparición de los PCs introdujo un cambio muy importante en las arquitecturas monolíticas y las aplicaciones para ellas desarrolladas. Las nuevas aplicaciones basadas en el paradigma cliente/servidor permitieron que parte del procesamiento realizado en el servidor fuese descargado a los PCs cliente. Las aplicaciones cliente/servidor normalmente distribuyen los componentes de la aplicación de forma que la base de datos reside en el servidor, el interfaz de usuario reside en el cliente, y la lógica de negocio puede residir tanto en el cliente (en forma de código), como en el servidor (en forma de procedimientos almacenados) o en ambos. Con la llegada de la arquitectura cliente/servidor multicapa la arquitectura cliente/servidor original pasó a llamarse cliente servidor de dos capas.

Ilustración 2. Arquitectura cliente/servidor de dos capas
La arquitectura cliente/servidor fue en algunos aspectos
una revolución que cambió la vieja forma en que se hacían las cosas. A pesar de
resolver muchos de los problemas de las aplicaciones basadas en mainframes, la
arquitectura cliente/servidor tenía sus propios problemas. Por ejemplo, como la
lógica de negocio y el acceso a la base
de datos estaban contenidos normalmente en la parte cliente, cualquier cambio
de la lógica de negocio, en el acceso a la base de datos o en la propia base de
datos requerirá a menudo actualizar la parte cliente de todos los usuarios de
la aplicación. Los problemas con esta tradicional arquitectura
cliente/servidor, a menudo denominada cliente/servidor de dos capas fueron
resueltos con lo que se conoce con el nombre de cliente/servidor multicapa.
Conceptualmente, una aplicación puede tener cualquier número de capas, pero las
arquitecturas multicapa suelen tener sólo tres capas. Estas arquitecturas
dividen la arquitectura del sistema en tres capas lógicas:
·
La capa de interfaz con el usuario.
·
La capa de reglas o lógica de negocio.
·
La capa de acceso a la base de datos.
De esta forma, el
cliente es básicamente una interfaz, que no tiene por qué cambiar si cambian
las especificaciones del negocio.
Las arquitecturas cliente/servidor multicapa mejoran a las arquitecturas de
dos capas en dos aspectos fundamentalmente:
- Hace a la
aplicación más robusta al aislar al cliente de los cambios en el resto de
la aplicación. La capa de interfaz de usuario se comunica solo con la capa
de lógica de negocio, nunca directamente con la capa de acceso a la base
de datos. La capa de lógica de negocio se comunica por un lado con la capa
de interfaz de usuario y por otro lado con la capa de acceso a la base de
datos. De esta forma un cambio en la base de datos no afecta a la parte
cliente que recordemos que es la que tiene que ser redistribuida si se
producen cambios en ella.
2.
Dado que
la arquitectura multicapa particiona la aplicación en
más componentes que la arquitectura tradicional cliente/servidor, también
permite una mayor flexibilidad en la utilización de la aplicación.

Ilustración
3. Arquitectura cliente/servidor de tres capas
El esfuerzo de desarrollo de un sistema con esta
arquitectura es mayor que en una clásica arquitectura cliente-servidor de dos
capas, pero este mayor esfuerzo inicial se ve compensado por unas importantes
mejoras en el mantenimiento y en la flexibilidad del sistema generado. No
olvidemos que en la mayoría de los
casos los gastos de mantenimiento son mucho mayores que los gastos de
desarrollo de la aplicación.
Arquitectura cliente/servidor de tres capas
Como se vio en el punto anterior, en la
arquitectura cliente/servidor de tres capas, existe una separación entre la
presentación de los datos, la lógica de negocio y el acceso a la base de datos.
Sin embargo, la manera de distribuir estas capas entre los equipos puede variar,
dando lugar a varios tipos de arquitecturas:
Presentación remota
La capa de presentación de datos, se ejecuta en el cliente totalmente. En ella se realizan las validaciones de los datos de entrada, el formateo de los de salida, etc. La lógica de negocio y el acceso a la base de datos se aloja en el servidor.
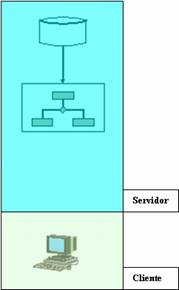
Ilustración 4. Modelo de presentación remota
Presentación distribuida
La capa de presentación se encuentra distribuida entre el cliente y el servidor, de manera que en el cliente se modifica o adapta la presentación que ofrece el servidor. Este tipo de sistemas tienen un difícil mantenimiento.

Ilustración 5. Modelo de presentación distribuida
Proceso distribuido
En este modelo, la capa que
implementa la lógica de negocio se encuentra dividida entre el cliente y el
servidor. El acceso a la base de datos se encuentra en el servidor y la capa de
presentación en el cliente.

Ilustración 6. Modelo de proceso distribuido
Base de datos distribuida
Las capas de negocio y de presentación se
ejecutan completamente en el cliente, mientras que la base de datos está
distribuida entre el cliente y el servidor. Se requieren de mecanismos para
asegurar la coherencia en los datos.

Ilustración 7. Modelo de base de datos distribuida
Base de datos remota
Las capas de negocio y de presentación se ejecutan completamente en el cliente, mientras que la base de datos está completamente en el servidor.

Ilustración 8. Modelo de base de datos remota
Homogeneidad de máquinas
En el mercado, nos podemos encontrar con
multitud de ordenadores de distintos fabricantes y tipos. Por regla general,
las comunicaciones entre ordenadores del mismo tipo no tienen por que suponer
demasiados problemas, ya que se podría decir que ambos “entienden” el mismo lenguaje. Sin embargo
cuando se intentan comunicar por red ordenadores de distinto tipo surgen
problemas relacionados con el tratamiento que internamente realizan con los
datos. Por ejemplo, el tipo float de C,
una vez compilado, puede ocupar distinto número de bytes
en una máquina que en otra. En concreto, los problemas más usuales son los
siguientes:
·
Tamaños distintos: en distintas máquinas, o mejor
dicho, distintos compiladores, un mismo tipo de datos puede tener tamaños
distintos. Por ejemplo, un entero, podría ocupar en una máquina 16 bits,
mientras que entra puede ocupar 32 bits.
·
Distinta representación: cada maquina tiene una manera
de representar ciertos datos. Por ejemplo, puede representar un número real de
una manera distinta al de otra máquina, o simplemente no tener capacidad para
representarlo directamente.
·
Distinta ordenación: la manera en que un ordenador
almacena la información en su memoria no es única. Esta característica se
conoce como endianity y exiten
dos posibilidades:
o
Little Endian: el byte de menor
peso se almacena en la dirección más baja de memoria. Este el modelo utilizado
en los PC.
o
Big Endian: el byte de menor
peso se almacena en la dirección más alta de memoria. Este el modelo utilizado
en los Apple Macintosh.
Esto implica que las interconexión de dos
máquinas no se puede ver como una conexión directa, en la que por un extremo
enviamos datos y por el otro los recibimos, ya que sencillamente, con este
modelo, las partes podrían no entenderse.

Ilustración 9. Comunicación sin adaptación de datos
La solución a este problema pasa por adaptar
los datos antes de su envío a un formato conocido tanto por el emisor como por
el receptor, de manera que al recibirlo, éste sea capaz de entenderlos y pueda
convertirlos a su representación nativa. Este elemento intermedio se conoce
como middleware, y se suele presentar como una
herramienta con la que cuenta el programador y que le adapta de manera
automática los datos. Para ello el programador no tiene más que definir (en un
lenguaje de representación de datos) los tipos de datos que desea enviar, y
está herramienta generará el código necesario para su envío, haciendo que la
operación de transformación sea transparente al programador.
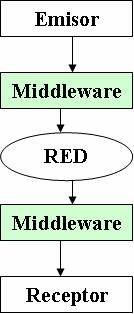
Ilustración 10. Comunicación con adaptación de datos